1. Null in Java 11
In Java, primitive values such as int and boolean are never null. So we
only need to consider the values of the reference types. However, you should
be careful with boxing/unboxing primitive types to/from their wrapper-classes
such as Integer and Boolean.
Null object pattern
Consider an example that when a key is pressed, the action associated with the key is performed:
...
public final class Main {
private final Map<Character, Runnable> map;
public Main() {
map = new HashMap<>();
map.put('h', () -> moveCursorLeft());
map.put('j', () -> moveCursorDown());
map.put('k', () -> moveCursorUp());
map.put('l', () -> moveCursorRight());
}
public void handleKeyInput() {
var c = getPressedKey();
var action = map.get(c);
// Since 'action' can be null, the next statement may throw
// a NullPointerException.
action.run();
}
/**
Returns the character of the pressed key.
If no key is pressed, blocks until any key is pressed.
@return
The character of the pressed key.
*/
private char getPressedKey() {
...
}
...
Because the get(Object) method of the Map interface can return null, you
need to add code to check whether the return value is null or not, that is, a
null check:
private void handleKeyInput() {
var c = getPressedKey();
var action = map.get(c);
if (action == null) {
// Does nothing with keys not associated with actions.
return;
}
action.run();
}
What does this null check represent? If you use
if—else if—else or switch instead of Map, you find the
process described in else or default corresponds to it (See #20 Prefer
subtyping to branching ).
Note that
ifandswitchincrease cyclomatic complexity and make testing cumbersome. Besides, forgetting to writeelseordefaultdoesn't cause errors at both compile and run time immediately, so it's hard to notice your mistakes.
Well, we can remove this null check as follows:
private static final Runnable DO_NOTHING = () -> {};
...
private void handleKeyInput() {
var c = getPressedKey();
// Of course, you can pass the method reference to an empty method
// instead of 'DO_NOTHING'.
var action = map.getOrDefault(c, DO_NOTHING);
action.run();
// In fact, you don't need 'action' and can write:
//
// map.getOrDefault(c, DO_NOTHING)
// .run();
}
We replaced get(Object) with getOrDefault(Object, V). It returns
DO_NOTHING, which is a Runnable to do nothing, instead of null for
characters not associated with any operation. Now all you need is only to
perform the returned operation, whether or not the character has been
associated with an operation. And if for the null check disappeared by
shuffling off it on the library.
Thus, the technique of using a special object instead of null is called
Null object pattern [1].
The book Refactoring [2] describes it within Introduce Null Object.
As usual, this pattern is not a silver bullet. It often works well when an
object like Runnable or Consumer to do nothing is useful. However, it may
not be appropriate when an object such as Function or Supplier is required.
Consider the following example:
interface Color {
/**
Returns the Color instance that matches with the specified name.
@param name
...
@return
{@code null} if nothing matches with {@code name}.
Otherwise, the instance that matches.
*/
static Color findByName(String name) {
...
}
/**
Returns the 24-bit integer value representing RGB.
@return
...
*/
int getRgb();
}
findByName(String), like get(Object) of Map, is a basic item of search
operations, which returns null if there is nothing else to look for. The
caller's code looks like as follows:
var yellow = Color.findByName("YELLOW");
// Since 'yellow' can be null, the next statement may throw a
// NullPointerException.
var rgb = yellow.getRgb();
You can finish with adding a null check, but what does happen when you
introduce something like a null object, as well as the previous Map example,
as follows:
interface Color {
/** Represents the invalid color. */
static final Color INVALID = () -> -1;
/**
Returns the Color instance that matches with the specified name.
@param name
...
@return
{@link INVALID} if nothing matches with {@code name}.
Otherwise, the instance that matches.
*/
static Color findByName(String name) {
...
}
...
Nobody knows the RGB value of the invalid color, so let's make INVALID return
−1 for now. That value is also a basic item. The caller's code would
then be:
var yellow = Color.findByName("YELLOW");
var rgb = yellow.getRgb();
// Needs to check whether or not 'rgb' is -1 after all.
The subsequent code can be executed without checking whether or not rgb is
−1. In some circumstances, such code is more dangerous. It is often
happier to throw an exception if the necessary null check is missing to prevent
the runtime from executing any further code.
Yup, it is important whether or not we do necessary checks, not whether or not
it is null. However, those checks themselves are the reason why the pseudo
null object pattern does not work. Imagine the inside of the
findByName(String) method, in which the following intrinsic check should have
already been implemented:
interface Color {
...
static Color findByName(String name) {
...
// The next 'if' statement is the intrinsic check.
if (/* The Color object associated with 'name' is not found. */) {
// Path A
return INVALID;
}
// Path B
return /* The Color object found successfully. */;
}
...
And the check of the caller's code should be as follows:
var yellow = Color.findByName("YELLOW");
var rgb = yellow.getRgb();
if (rgb == -1) {
// Executes the Process A.
} else {
// Executes the Process B.
}
That is, if the path A/B is passed at the intrinsic check, the caller
deterministically executes the Process A/B. Now you may have noticed that by
passing both Process A and Process B to findByName(String) additionally,
the caller no longer needs the return value and to check it. In short, you can
change a way to something like this:
interface Color {
...
static void findByName(String name, /* Process A */, /* Process B */) {
...
if (/* The Color object associated with 'name' is not found. */) {
// Executes the Process A.
return;
}
// Executes the Process B, with the Color object found successfully.
}
...
}
...
// The caller does not need the return value and to check it.
Color.findByName("YELLOW", /* Process A */, /* Process B */);
Optional class
This kind of operation, that is, the operation that gets information on the existence of a value and gets the value if it exists can be described as follows:
- Use the instance as the return value, which holds a value of the type
Tand anotherbooleanvalue indicating the existence of the value. - Add the parameters of
Consumer<T>to receive a value and ofRunnableto know of no value, instead of the return value.
In some languages, for example, the former can be implemented with tuples. The
latter is just to get results with the callback. Suppose you have a terrible
class like Pair<K, V> available, so the previous findByName method could be
rewritten as follows:
interface Color {
static Pair<boolean, Color> findByName(String name) {
...
}
static void findByName(String name,
Consumer<Color> found,
Runnable notFound) {
...
}
...
But if you keep up this way to write the API, your code will soon be full of boilerplates.
Fortunately, Java has Optional class†1 that
encapsulates these operations. Let's rewrite the previous example with the
Optional class:
†1
java.util.Optionalhas been added since Java 8.
interface Color {
/**
Returns the Color instance that matches with the specified name.
@param name
...
@return
An {@link Optional<T> Optional} object containing the Color
instance that matches with {@code name}, or an empty Optional
object (if nothing matches).
*/
static Optional<Color> findByName(String name) {
...
}
}
The caller's code would be as follows:
var yellow = Color.findByName("YELLOW");
yellow.ifPresent(c -> {
var rgb = c.getRgb();
System.out.println("yellow: rgb=" + rgb);
});
// Alternatively, we may write as follows, but...
var blue = Color.findByName("BLUE");
if (blue.isPresent()) {
var rgb = blue.get().getRgb();
System.out.println("blue: rgb=" + rgb);
}
If the Optional object has a value, the ifPresent(Consumer) method invokes
the argument of Consumer with the value as a parameter. If it doesn't, it
does nothing. It works by shuffling off the presence checks on the library.
On the other hand, the combination of isPresent() and get() is the worst,
and get() will just throw an exception if you forget to check with
isPresent() after all. Nothing changes.
Optional<T>also has methods to get the value such asorElse(T)andorElseGet(Supplier), specifying a default value and a lambda expression that returns the default value, respectively.
The type like this Optional class is called Option
type†2 [3].
†2 It is sometimes called Maybe type.
Although Java does not have, there is a Nullable type in some other
languages. This is slightly different from the option type. The option type
can be nested like Optional<Optional<T>>, but the nullable type cannot. The
nullable type is covered in the next C# part.
Let's digress a little bit from the main subject. The easy tasks have got easier to write, such as if YELLOW is found..., if BLUE is not found..., and so on. But the real tasks are harder. Could you smell something not easy if it has changed into if both YELLOW and BLUE are found...? You might think it can be as follows:
var yellow = Color.findByName("YELLOW"); yellow.ifPresent(c1 -> { var blue = Color.findByName("BLUE"); blue.ifPresent(c2 -> { // Process with 'c1' and 'c2' ... }); });That may be true. But what do you do if there are n colors to be found instead of two? There is a hint later. Think about it.
Collection and null
Is the Optional class just an encapsulation of a null check? Think about the
essence of it.
Here's an example of using the stream API:
var firstFavorite = List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.findFirst();
firstFavorite.ifPresent(s -> { ... });
// As a result, it is equivalent to the following code:
List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.findFirst()
.ifPresent(s -> { ... });
where matchesFavorite should be an appropriate Predicate<String>. Since
findFirst() of the Stream interface, which has been well thought out,
returns an instance of Optional<String> in this case, checking whether it has
the value or not must be required. If you dare to do the same thing without
using findFirst(), you'll get:
var favoriteList = List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.limit(1)
.collect(Collectors.toList());
The difference from before is that the return type has changed from
Optional<T> to List<T>. Even though it's a list, the number of elements in
the list is 0 or 1, or in cooler words, 1 at most. Therefore, this List<T>
is practically the same as Optional<T>, so it can continue as follows:
favoriteList.forEach(s -> { ... });
// Or
for (var s : favoriteList) {
// This loop only runs once at most.
...
}
// Or again, it could be as follows, but...
if (favoriteList.size() != 0) {
var s = favoriteList.get(0);
...
}
Thus, a version that dares not to use findFirst() can be written as
follows:
List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.limit(1)
.forEach(s -> { ... });
Of course, if you write such code in Java that has already had Optional<T>,
it would be fixed in the code review after all. If you see that Optional<T>
can be thought of as a special List<T> whose length is at most 1, you
should forget such code.
Even if you can use
Listinstead ofOptional, wrapping a value inArrayListgives us a lot of overhead. If you have the implementation class ofListwith a constraint of at most one element, you can do it as lightly asOptional. But even if you don't implement it yourself, Java has already hadCollections.singletonList(T)since long beforeOptionaldebuted, which can serve that purpose. You can use it andCollections.emptyList()to achieve something likeOptional. (Collections.singleton(T)andCollections.emptySet()) are also fine, but I've usedListhere for the explanation because getting an element from aSetis tedious.)
Now, let's put these together with “Item 43: Return empty arrays or collections, not nulls” in the book Effective Java [4], so it shows the following table:
| Number of instances | Types | null/Alternatives |
|---|---|---|
| At most 1 | T |
null |
| At most 1 | Optional<T> |
Optional<T>.empty() |
| 0 or more | T[] |
public static final T[] EMPTY = {}; |
| 0 or more | List<T> |
Collections.emptyList() |
| 0 or more | Stream<T> |
Stream<T>.empty() |
Whether a reference is null is a matter at the same level as whether the
array has zero elements. In the same tone as “Using int is a waste of
memory, so use short instead,” we just use a
reference†3, for an array is too heavy if the number of its
elements is at most one. Some people, who try to eradicate null, scream:
“It's not my fault. It's all
null's fault. It's no good because we don't use null-safe languages.”
Should they achieve their goal, they might now try to eliminate fixed-length arrays that require size checks.
†3 To explain something in detail, arrays are more expressive. With arrays, the information about the presence or absence of a value (i.e., whether the length of the array is 1 or 0) is independent of the value itself. So the element of the array itself can be
nullto represent that there is a value and the value isnull. On the other hand, if you represent the existence of a value with whether it is a null reference or not, it is impossible to set the value itself tonull.
Indirection of NULL pointers (or dereferencing NULL pointers) should not be
allowed in C and C++ because it is undefined behavior (See #28 Undefined
Behavior ). Java defines that it throws a NullPointerException when
dereferencing null, so null in Java is safer than NULL in C or C++. It
doesn't make sense to deal with things with such differences in the same way.
Problems with Optional
Does Optional solve everything for at most one? Of course not. As well as
returning an empty array instead of null does, it has the following problems:
Optionalis a reference type, not a primitive type- It is possible to invoke
get()without checking withisPresent() - There are still a lot of old APIs in the standard library that return or
accept
null - Using
Optionalfor everything that might benullsacrifices runtime performance
The first problem comes from the compiler not treating Optional specially.
It may happen that it seemed to be an Optional object but actually, it was
null. For example, the following code is surreal but not useful:
Optional<String> maybeString = null;
or:
public Optional<String> getMaybeString() {
return null;
}
Of course, a method with a return type of Optional<T> can return null, and
you can pass null to a method that accepts parameters of type Optional<T>.
However, even if the current Java boxed null with Optional<T>.empty(),
there would be a lot of trouble.
The second problem is also a compiler problem. It is possible to delay the
discovery of the bugs that could be found at compile time with static analysis
until throwing a NoSuchElementException at run time.
The third problem is how to deal with legacy APIs. You should properly
integrate the old APIs with null and the new APIs with Optional.
The last problem, although that's the usual, is that there are a lot of people who don't allow sacrificing performance at run time.
Compiler's static analysis
Combining the compiler's static analysis (data-flow analysis) with annotating the source code with metadata allows us to know at compile time whether the null check of the value of the reference type is appropriate. Although not currently included in the JDK, there are static analysis tools as follows:
The following IDEs also provide a similar mechanism:
- IntelliJ IDEA
- Eclipse
- Android Studio
However, the classes used in annotations have not yet been
standardized†4. Therefore, it should be noted that each
implementation defines its similar annotation classes (e.g., @NonNull,
@NotNull, @Nonnull, and so on), which are not compatible with each other.
†4 JSR-305 and JSR-308 try to standardize them. See below for why there are too many annotation classes competing with one another:
https://stackoverflow.com/questions/4963300/which-notnull-java-annotation-should-i-use
Using an implementation of IntelliJ IDEA as an example, @NotNull and
@Nullable annotate fields, parameters, return values, and so on as follows:
public final class ContactInfo {
private @NotNull String name;
private @NotNull List<@NotNull String> mailList;
private @Nullable Integer age;
public ContactInfo(@NotNull String name,
@NotNull List<@NotNull String> mailList,
@Nullable Integer age) {
this.name = name;
this.mailList = Collections.unmodifiableList(mailList);
this.age = age;
}
...
public @Nullable String getPrimaryMail() {
var list = mailList;
return list.size() == 0 ? null : list.get(0);
}
...
public @Nullable Integer getAge() {
return age;
}
}
Then you get the following code ready to use this ContactInfo class:
public final class Main {
private static void sendMail(@NotNull String mailAddress,
@NotNull String name) {
System.out.println(mailAddress + " " + name);
}
public static void main(String[] args) {
var listContainingNull = new ArrayList<String>();
listContainingNull.add(null);
var infoList = List.of(
new ContactInfo("Jack", listContainingNull, null),
new ContactInfo("Jack", List.of("jack@example.com"), null),
new ContactInfo("Kim", Collections.emptyList(), 18));
infoList.stream()
.filter(i -> i.getAge() < 20)
.forEach(i -> sendMail(i.getPrimaryMail(), i.getName()));
}
}
With IntelliJ IDEA, you click Analyze ➜ Inspect Code..., and then get the following result:
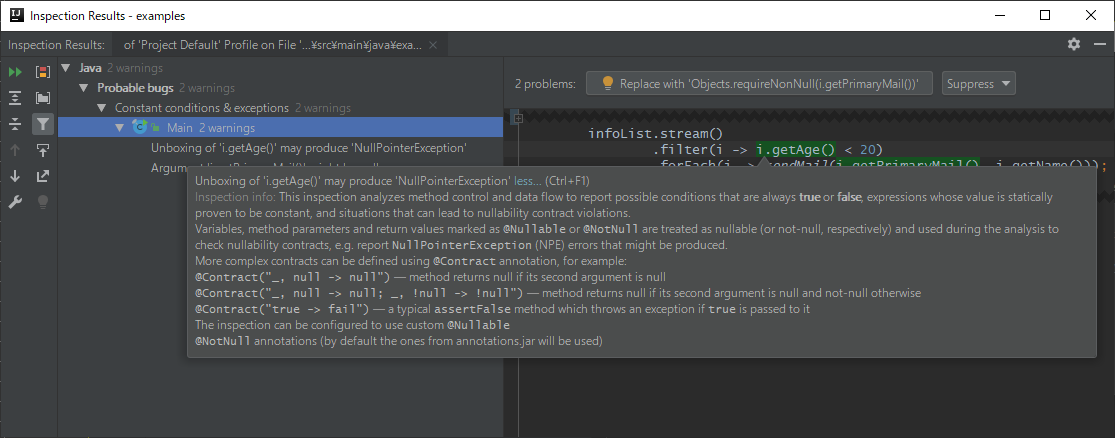
Certainly, the indication is correct, because getAge() can return null.
That is, a null check is necessary, but it is unboxing without a null check.
Similarly, the following indication:

This is also true. The first parameter of sendMail which should not be
null is specified with the return value of i.getPrimaryMail() which can be
null.
However, passing listContainingNull to the second parameter of the
constructor of ContactInfo is ignored. Annotations to type
parameters like List<@NotNull String> don't seem to work.
However, once these annotations are standardized and
practical†5, the needs for strange boilerplates (which are
ceremonies to check whether the value of the argument is null at the
beginning of the public method) and
the APIs for them are eliminated.
†5 Static analysis cannot be perfect. False positives and false negatives just will not go away. Also, metadata is fed by humans, so if an API is incorrectly annotated, then a catastrophe follows.
Quarantine policy
Unfortunately, the annotations related to null are just a proof of concept
(PoC) until all the necessary APIs in the standard library have metadata fed
and the compiler can issue warnings. In Java and other languages without null
safety, a practical way to prevent null from the landing is to take the
following quarantine measures against null:
- Do not to use
nullas much as possible - If using the APIs that may return/accept
null, check whether it isnullas soon as possible — Do not defer anullcheck - If it is
null, quickly dispose of it, for example, by converting it to another suitable expression — Do not defer disposition ofnull
Deferring the disposition of null is, for example, as follows:
- Shuffle off
nullon other innocent objects (But, of course, passingnullto the classes for that purpose like theofNullable(T)method ofOptional<T>is good) - Propagate
nullto another type†6 - Convert
nullto an irrelevant null object - Catch
NullPointerException†7
†6 An example of propagation to another type:
(s == null) ? null : s.getValue()
†7 Without limited to
NullPointerException, we shouldn't catchRuntimeExceptionand its derived exceptions, but...
In Java, in particular, you can wrap immediately a reference that might be
null with Optional.ofNullable(T), and then check and dispose of it. Don't
leave it wrapped.
Fountains of null
If you can take quarantine measures, all you need is to avoid creating null
as much as possible. A typical source of null in Java may be uninitialized
fields, array creation, and uninitialized local variables as follows:
// Uninitialized fields
private String name;
public void foo() {
// Array creation (all the elements are null)
var array = new Object[SIZE];
// Uninitialized local variables
String s;
...
}
Since not all classes can be immutable†8, there are of course
fields that change their values according to the state of the instance.
However, there is no necessity for such fields to be null. For example, if
null means that its value is not assigned, instead of using null, you can
change the type of the field from T to Optional<T> and assign
Optional<T>.empty() to represent it.
†8 Simple examples are two instances of cross-referencing, a list of circular references, and so on.
If a particular field may be null in any state of the instance, then all
accesses to that field require a null check, so that wrapping it with
Optional<T> makes sense. Or, in some cases, the state of the instance
determines whether the field is null. For example, if you are in a situation
where certain fields are guaranteed not to be null while calling a private
instance method, to reconsider your design by splitting classes, applying state
patterns, etc. may improve your well-being.
You should also create arrays with the terminal operations of the stream API as much as possible, allowing direct array creation only if you can't†9.
†9 What immediately comes to mind is the implementation of a hash table, etc.
Finally, local variables. You should assign the initial values to local variables always when they are declared. New hires, and somebodies with as much skill as they have, often seem to be smug, with writing the following code:
String s;
if (state == State.A) {
s = ...
} else {
s = ...
}
In some cases, it can be written as a ternary operator (or switch expression
in Java 12). Otherwise, you can separate it into another method that returns a
value such as var s = method();. Or, if the separation causes a lot of
parameters, you can define Supplier or Function (i.e., lambda expressions)
and assign the return value of the expression. (You can use local functions
instead of lambda expressions in C#.)
There are many similar cases of uninitialized local variables. For example, with
try—catch, you must avoid declaring a local variable without initialization just beforetryand then assigning a value to the variable in atryblock.